這款升級版AI視頻生成器新增了音效和精準編輯工具,表明谷歌正加緊挑戰OpenAI的Sora 2。

谷歌今日發布了其AI視頻生成器Veo的更新版本——Veo 3.1。此版本為所有功能添加了音頻支持,并引入了新的編輯功能,旨在讓創作者對其視頻片段擁有更多控制權。
此次發布之際,正值OpenAI的競爭產品Sora 2應用在應用商店榜單上攀升,并引發了關于AI生成內容充斥社交媒體的討論。
這一時機選擇表明,谷歌希望將Veo 3.1定位為Sora 2那種病毒式社交傳播方式的專業替代品。OpenAI于9月30日推出了Sora 2,其界面采用TikTok風格,優先考慮分享和混剪功能。
該應用在五天內下載量達到100萬次,并登頂蘋果App Store排行榜。Meta也采取了類似策略,推出了其由AI視頻驅動的虛擬社交媒體平臺。
用戶現在可以使用"多圖成視頻"工具,創建帶有同步環境噪音、對話和擬音效果的視頻。該工具可將多張參考圖像組合成單個場景。
"幀間動畫"功能可生成起始圖像和結束圖像之間的過渡效果,而"延長"功能則通過延續現有視頻最后一秒的運動,生成最長可達一分鐘的視頻片段。

新的編輯工具允許用戶在生成的場景中添加或移除元素,并自動調整陰影和光照。該模型可生成1080p分辨率、橫屏或豎屏比例的視頻。
該模型通過Flow向普通用戶開放,通過Gemini API向開發者開放,并通過Vertex AI向企業客戶開放。使用"延長"功能可以創建最長一分鐘的視頻,該功能能夠延續現有片段最后一秒的運動。
2025年,AI視頻生成市場變得異常擁擠:Runway的Gen-4模型面向電影制作人,Luma Labs為社交媒體提供快速生成服務,Adobe將Firefly Video集成到Creative Cloud中,而xAI、Kling、Meta和谷歌的更新則專注于提升真實感、音效生成和提示詞遵循能力。
但它到底有多好呢?我們對其進行了測試,以下是我們的一些印象。
模型測試
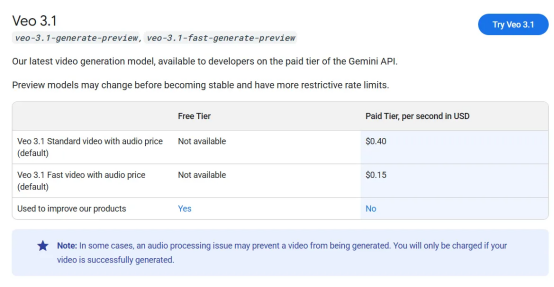
如果你想嘗試它,最好準備充足的預算。Veo 3.1是目前最昂貴的視頻生成模型,與Sora 2價格相當,僅低于每次生成費用是其二倍多的Sora 2 Pro。
免費用戶每月收到100點信用額度來測試系統,這大約足夠每月生成五個視頻。通過Gemini API,帶音頻的Veo 3.1視頻生成成本約為每秒0.40美元,而一個名為Veo 3.1 Fast的更快變體成本為每秒0.15美元。
對于愿意以此價格使用的用戶,以下是它的優缺點。
Veo 3.1相比其前身確實有所改進。該模型能很好地處理連貫性,并表現出對上下文環境更好的理解能力。
它適用于不同的風格,從照片寫實主義到風格化內容。
我們要求模型融合一個場景,該場景從繪圖開始,逐漸過渡到實景鏡頭。它處理這項任務的表現優于我們測試過的任何其他模型。
在沒有任何參考幀的情況下,Veo 3.1在文生視頻模式下產生的結果,比使用相同提示詞但附帶初始圖像時產生的結果更好,這令人驚訝。
其代價是運動速度。Veo 3.1優先考慮連貫性而非流暢度,這使得生成快節奏動作具有挑戰性。
元素移動較慢,但在整個片段中保持一致性。在快速運動方面,Kling仍然領先,盡管它需要更多嘗試才能獲得可用的結果。
Veo憑借圖生視頻功能建立了聲譽,而其效果總體上仍令人滿意——但存在注意事項。這似乎是本次更新的一個較弱環節。當使用不同寬高比的圖像作為起始幀時,模型難以維持它曾經擁有的連貫性水平。
如果提示詞與輸入圖像邏輯上應有的后續內容偏離太遠,Veo 3.1會設法"作弊"。它會生成不連貫的場景,或者在位置、布景或完全不同的元素之間跳躍的片段。
這既浪費時間又浪費信用點,因為這些片段因格式不匹配而無法編輯成更長的序列。
當它成功工作時,效果看起來非常棒。但達到理想效果部分靠技巧,部分靠運氣——而且主要是靠運氣。
元素成視頻
此功能類似于視頻修復,允許用戶在場景中插入或刪除元素。但不要期望它能保持完美的連貫性或完全使用你提供的精確參考圖像。
例如,下面的視頻是使用以下三張參考圖和提示詞生成的:"一男一女在未來城市中奔跑時偶然相遇,那里有一個比特幣標志的全息圖在旋轉。男子對女子說:'快,比特幣暴跌了!我們必須買入更多!!'"

無論是城市還是角色都并非嚴格按照參考圖呈現。
然而,角色穿著參考圖中的衣服,城市也與圖片中的城市相似,事物呈現的是元素的"概念",而非元素本身。
Veo 3.1將上傳的元素視為靈感來源,而非嚴格的模板。它會生成遵循提示詞并包含與你提供的對象相似之物的場景,但別浪費時間試圖把自己插入到電影中——那是行不通的。
一個變通方法是:先使用Nanobanana或Seedream上傳元素并生成一個連貫的起始幀,然后將該圖像喂給Veo 3.1,這樣它生成的視頻中,角色和物體在整個場景中的形變會最小。
帶對話的文生視頻
這是谷歌的賣點。Veo 3.1在唇形同步方面的處理能力優于當前任何其他可用模型。在文生視頻模式下,它能生成與場景元素匹配的連貫環境音。
其對話、語調、聲音和情感都非常準確,擊敗了競爭對手。
其他生成器可以產生環境噪音,但只有Sora、Veo和Grok能生成實際的詞語。
在這三者中,Veo 3.1在文生視頻模式下獲得良好結果所需的嘗試次數最少。
帶對話的圖生視頻
這正是問題所在之處。帶對話的圖生視頻存在與標準圖生視頻相同的問題。Veo 3.1過于優先考慮連貫性,以至于忽略了對提示詞的遵循和參考圖像。
例如,這個場景是使用"元素成視頻"部分展示的參考圖生成的。
如你所見,我們的測試生成了一個與參考圖像完全不同的主體。視頻質量非常出色——語調和手勢都很到位——但那不是我們上傳的人,使得結果毫無用處。
對于這個用例,Sora的混音功能是最佳選擇。該模型可能受到內容審查,但其圖生視頻能力、逼真的唇形同步以及對語調、口音、情感和真實感的關注,使其成為明顯的贏家。
Grok的視頻生成器位居第二。它比Veo 3.1更好地尊重了參考圖像,并產生了更優的結果。這里是使用相同參考圖像和提示詞的一次生成樣例。
如果你不想折騰Sora的社交應用,或者無法使用它,Grok可能是你的最佳選擇。它同樣未經審查但受監管,所以如果你需要那種特定的方式,馬斯克已經為你考慮到了。
精選文章: